I have during January spent a lot of time thinking about, reading about and setting up a Service Level Agreement. The purpose is to agree on measurable metrics like uptime, responsiveness and responsibilities with your paying clients.
If it’s done right, it will influence how those clients prefer to interface to you. If they do it synchronously, asynchronously, put a cache in-between or have a failsafe.
Here I will write some general insights that I got from this process. If you want my complete SLA convention, you should check out my wiki. There I’ve also posted a sample SLA that you can reuse for your own purposes.
Always Start with Metrics
Before you dig into availability and 99.99999% you must start with metrics. What does availability mean to you? How do you measure it? What is an error? Is http status 404 an error? Does errors during maintenance count towards your metric? How is request latency measured? Is it measured on the client or the server? Do you measure the average on all the requests? How does a cold start latency affect your metric?
There are a lot of things to unpack before you can start thinking about objectives.

Not as Available as you Think
Everywhere you look businesses offer a 99,95% availability. Translated, it means 5 minutes and 2 seconds downtime weekly. A common misconception from developers is that it’s easy – All our deploys are automated anyway and if one fails, we’ll just rollback.
Before you set that objective you should consider
- When the service goes down in the middle of the night, how much time does it take to wake somebody up to take look at the problem?
- When the service goes down Saturday morning, do you have people working through the weekend to get the service up and running again?
- Your availability is dependent on the availability of all the services you depend on. If you host on Azure Kubernetes which offers 99,95% availability, you cannot offer the same because Microsoft will eat up your whole failure budget.
Be kind to yourself. Don’t overpromise
- Set an objective that promises availability within business hours, when you have developers awake that can work on the problem.
- Pay people to be on-call when you need to offer availability off-hours.
- Multiply availability of your dependent services with each other, and then with your own availability to reach a reasonable number. And then give yourself some slack. An objective should not be impossible or even challenging.
Azure Kubernetes = 99.95%
Azure MySQL = 99.9%
Azure API Management = 99.95%
My availability = 99%
Total Availability = 99.95% * 99.9% * 99.95% * 99% = 98.8%Every Metric must be Measured
This sound so obvious, how can you know that you meet the objective unless you measure the metric? Still I rarely see anyone measuring their service level indicators. Maybe they don’t want to know.
If you are using a cloud provider like Microsoft Azure, you can setup workbooks to measure your metrics. I’m a proponent of giving my clients access to these workbooks so they can see that we live up to the SLA.
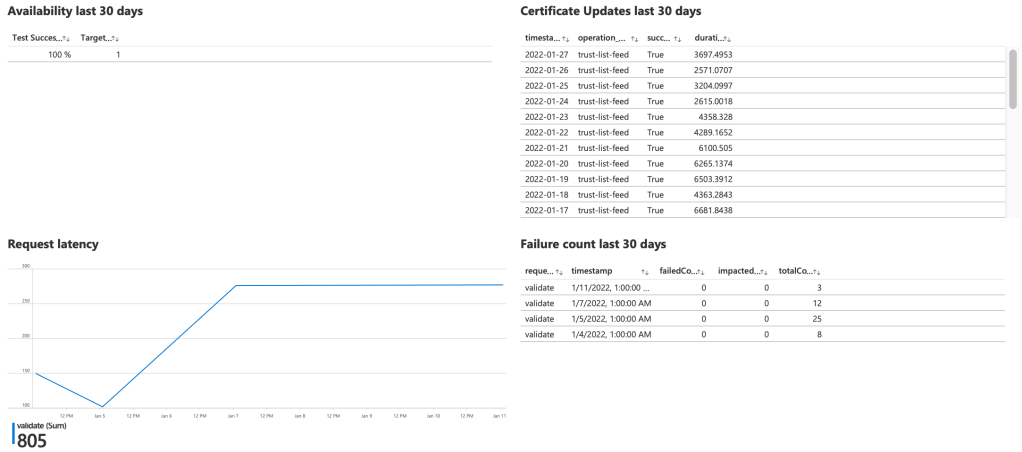
The Client Also have Responsibilities
An agreement goes both ways, and in order for you as a vendor to fulfil your part of the agreement you need to put some requirements on the client.
- Define a reasonable workload that the client is allowed to put on your service for the objectives to be obtainable. You can set a limit of 100 requests/second and refuse excess requests. Those errors do not count towards your error budget.
- The client should be responsible for adjusting their service clients to updates in your API. You don’t want to maintain a 5 year old version of your system.
Reparations should Repair not Bankrupt
I’ve seen so many service license agreements that include a fine if the objectives are not met, and often those fines are quite high. They seldom define how often a client can request a payout, and together with badly defined objectives, a client could drive a service provider into bankruptcy.
That is not beneficial to anyone, so please stop writing SLAs with harsh penalties. You should try to repair and not bankrupt
- How much damage was caused by the outage?
- Can we update the service level objectives to become more reasonable?
- Can the client adjust their use of our service to better fit our new objectives?
- Is the client open to paying more so we can have a service technician on-call?
Summary
Writing an SLA is hard. It requires experience from both the legal team and IT operations. Availability is not an objective that a client can demand of your service. It must be negotiated and carefully weighed between IT operations environment, support organization and costs.
